Packaging#
This section describes practices to follow when packaging your own models or datasets to be used along with EVA.
Models#
Please follow the following steps to package models:
Create a folder with a descriptive name. This folder name will be used by the UDF that is invoking your model.
- Place all files used by the UDF inside this folder. These are typically:
Model weights (The .pt files that contain the actual weights)
Model architectures (The .pt files that contain model architecture information)
Label files (Extra files that are used in the process of model inference for outputting labels.)
Other config files (Any other config files required for model inference)
Zip this folder.
Upload the zipped folder to this link inside the models folder.
Datasets#
Please follow the following steps to package datasets:
Create a folder for your dataset and give it a descriptive name.
This dataset folder should contain 2 sub-folders named ‘info’ and ‘videos’. For each video entry in the videos folder, there should be a corresponding CSV file in the info folder with the same name. The structure should look like:
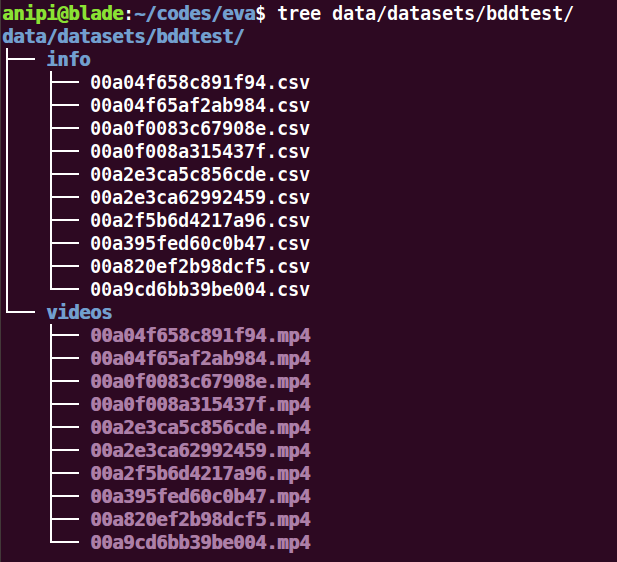
The videos folder should contain the raw videos in a standard format like mp4 or mov.
The info folder should contain the meta information corresponding to each video in CSV format. Each row of this CSV file should correspond to 1 unique object in a given frame. Please make sure the columns in your CSV file exactly match to these names. Here is a snapshot of a sample CSV file:

- The columns represent the following:
id - (Integer) Auto incrementing index that is unique across all files (Since the CSV files are written to the same meta table, we want it to be unique across all files)
frame_id - (Integer) id of the frame this row corresponds to.
video_id - (Integer) id of the video this file corresponds to.
dataset_name - (String) Name of the dataset (should match the folder name)
label - (String) label of the object this row corresponds to.
bbox - (String) comma separated float values representing x1, y1, x2, y2 (top left and bottom right) coordinates of the bounding box
object_id - (Integer) unique id for the object corresponding to this row.
Zip this folder.
Upload the zipped folder to this link inside the datasets folder.
Note: In the future, will provide utility scripts along with EVA to download models and datasets easily and place them in the appropriate locations.