Custom Model Tutorial#
|
|
 View source on GitHub View source on GitHub
|
|
Start EVA server#
We are reusing the start server notebook for launching the EVA server.
!wget -nc "https://raw.githubusercontent.com/georgia-tech-db/eva/master/tutorials/00-start-eva-server.ipynb"
%run 00-start-eva-server.ipynb
cursor = connect_to_server()
File '00-start-eva-server.ipynb' already there; not retrieving.
[ -z "$(lsof -ti:5432)" ] || kill -9 $(lsof -ti:5432)
nohup eva_server > eva.log 2>&1 &
WARNING: Running pip as the 'root' user can result in broken permissions and conflicting behaviour with the system package manager. It is recommended to use a virtual environment instead: https://pip.pypa.io/warnings/venv
Note: you may need to restart the kernel to use updated packages.
Download custom user-defined function (UDF), model, and video#
# Download UDF
!wget -nc https://www.dropbox.com/s/lharq14izp08bfz/gender.py
# Download built-in Face Detector
!wget -nc https://raw.githubusercontent.com/georgia-tech-db/eva/master/eva/udfs/face_detector.py
# Download models
!wget -nc https://www.dropbox.com/s/0y291evpqdfmv2z/gender.pth
# Download videos
!wget -nc https://www.dropbox.com/s/f5447euuuis1vdy/short.mp4
File 'gender.py' already there; not retrieving.
File 'face_detector.py' already there; not retrieving.
File 'gender.pth' already there; not retrieving.
File 'short.mp4' already there; not retrieving.
Load video for analysis#
cursor.execute("DROP TABLE TIKTOK;")
response = cursor.fetch_all()
print(response)
cursor.execute("LOAD VIDEO 'short.mp4' INTO TIKTOK;")
response = cursor.fetch_all()
print(response)
cursor.execute("""SELECT id FROM TIKTOK WHERE id < 5""")
response = cursor.fetch_all()
print(response)
@status: ResponseStatus.FAIL
@batch:
None
@error: Table: TIKTOK does not exist
@status: ResponseStatus.SUCCESS
@batch:
0
0 Number of loaded VIDEO: 1
@query_time: 0.09735049899973092
@status: ResponseStatus.SUCCESS
@batch:
tiktok.id
0 0
1 1
2 2
3 3
4 4
@query_time: 0.08554376400024921
Visualize Video#
from IPython.display import Video
Video("short.mp4", embed=True)
Create GenderCNN and FaceDetector UDFs#
cursor.execute("""DROP UDF GenderCNN;""")
response = cursor.fetch_all()
print(response)
cursor.execute("""CREATE UDF IF NOT EXISTS
GenderCNN
INPUT (data NDARRAY UINT8(3, 224, 224))
OUTPUT (label TEXT(10))
TYPE Classification
IMPL 'gender.py';
""")
response = cursor.fetch_all()
print(response)
cursor.execute("""CREATE UDF IF NOT EXISTS
FaceDetector
INPUT (frame NDARRAY UINT8(3, ANYDIM, ANYDIM))
OUTPUT (bboxes NDARRAY FLOAT32(ANYDIM, 4),
scores NDARRAY FLOAT32(ANYDIM))
TYPE FaceDetection
IMPL 'face_detector.py';
""")
response = cursor.fetch_all()
print(response)
@status: ResponseStatus.FAIL
@batch:
None
@error: UDF GenderCNN does not exist, therefore cannot be dropped.
@status: ResponseStatus.SUCCESS
@batch:
0
0 UDF GenderCNN successfully added to the database.
@query_time: 11.116637402999913
@status: ResponseStatus.SUCCESS
@batch:
0
0 UDF FaceDetector already exists, nothing added.
@query_time: 0.011710384999787493
Run Face Detector on video#
cursor.execute("""SELECT id, FaceDetector(data).bboxes
FROM TIKTOK WHERE id < 10""")
response = cursor.fetch_all()
print(response)
@status: ResponseStatus.SUCCESS
@batch:
tiktok.id facedetector.bboxes
0 0 [[ 90 208 281 457]]
1 1 [[ 91 208 281 457]]
2 2 [[ 90 207 283 457]]
3 3 [[ 90 207 284 458]]
4 4 [[ 90 208 282 460]]
5 5 [[ 89 209 283 460]]
6 6 [[ 88 208 283 461]]
7 7 [[ 89 206 282 464]]
8 8 [[ 90 224 281 469]]
9 9 [[ 94 234 279 468]]
@query_time: 0.3409588349995829
Composing UDFs in a query#
Detect gender of the faces detected in the video by composing a set of UDFs (GenderCNN, FaceDetector, and Crop)
cursor.execute("""SELECT id, bbox, GenderCNN(Crop(data, bbox))
FROM TIKTOK JOIN LATERAL UNNEST(FaceDetector(data)) AS Face(bbox, conf)
WHERE id < 50;""")
response = cursor.fetch_all()
print(response)
@status: ResponseStatus.SUCCESS
@batch:
tiktok.id Face.bbox gendercnn.label
0 0 [90, 208, 281, 457] female
1 1 [91, 208, 281, 457] female
2 2 [90, 207, 283, 457] female
3 3 [90, 207, 284, 458] female
4 4 [90, 208, 282, 460] female
5 5 [89, 209, 283, 460] female
6 6 [88, 208, 283, 461] female
7 7 [89, 206, 282, 464] female
8 8 [90, 224, 281, 469] female
9 9 [94, 234, 279, 468] female
10 10 [94, 231, 280, 469] female
11 11 [93, 232, 278, 470] female
12 12 [94, 232, 280, 469] female
13 13 [94, 226, 281, 468] female
14 14 [93, 225, 281, 469] female
15 15 [92, 222, 281, 471] female
16 16 [91, 220, 282, 472] female
17 17 [91, 219, 282, 472] female
18 18 [91, 224, 280, 471] female
19 19 [91, 229, 278, 470] female
20 20 [90, 228, 277, 469] female
21 21 [86, 220, 278, 474] female
22 22 [86, 220, 277, 473] female
23 23 [87, 223, 276, 472] female
24 24 [85, 221, 276, 473] female
25 25 [86, 223, 276, 473] female
26 26 [87, 222, 277, 472] female
27 27 [87, 222, 277, 472] female
28 28 [89, 222, 278, 471] female
29 29 [92, 221, 279, 468] female
30 30 [95, 222, 280, 468] female
31 31 [97, 222, 282, 470] female
32 32 [98, 219, 286, 472] female
33 33 [99, 223, 286, 472] female
34 34 [98, 224, 287, 471] female
35 35 [99, 223, 288, 471] female
36 36 [102, 223, 288, 471] female
37 37 [101, 223, 290, 472] female
38 38 [100, 213, 292, 472] female
39 39 [98, 210, 293, 473] female
40 40 [98, 211, 292, 472] female
41 41 [97, 211, 291, 472] female
42 42 [96, 211, 291, 472] female
43 43 [96, 212, 290, 471] female
44 44 [96, 212, 289, 470] female
45 45 [94, 213, 289, 470] female
46 46 [94, 213, 289, 470] female
47 47 [94, 214, 288, 470] female
48 48 [95, 217, 285, 470] female
49 49 [95, 221, 285, 471] female
@query_time: 2.6860659730000407
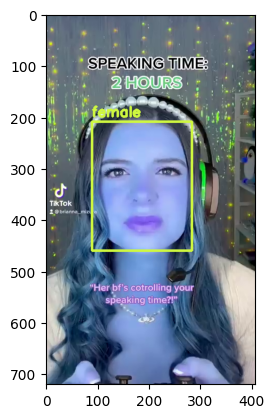
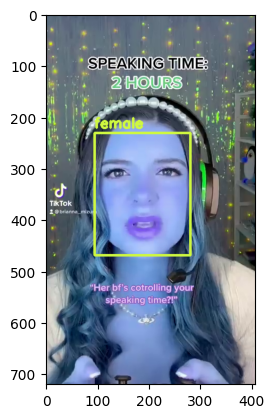
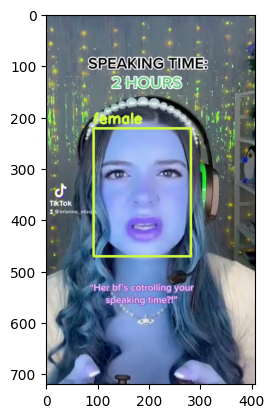
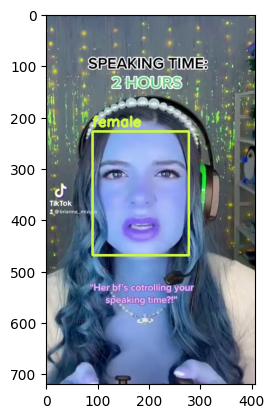
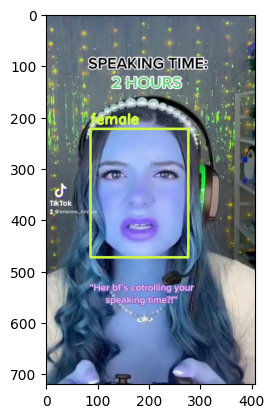
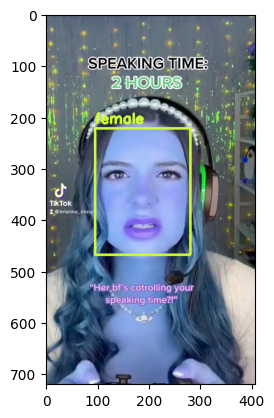
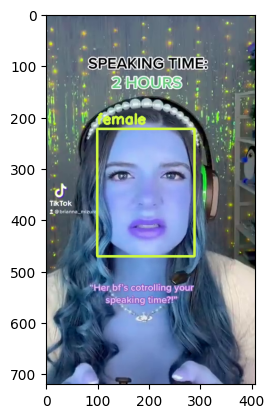
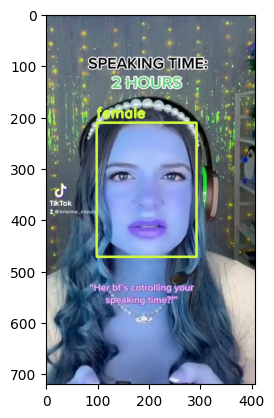
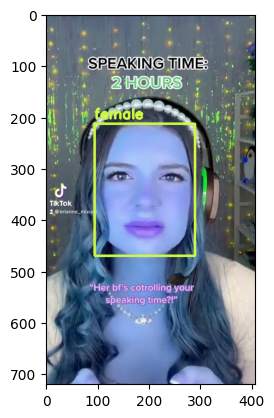
Visualize Output#
import cv2
from matplotlib import pyplot as plt
def annotate_video(detections, input_video_path, output_video_path):
color=(207, 248, 64)
thickness=4
vcap = cv2.VideoCapture(input_video_path)
width = int(vcap.get(3))
height = int(vcap.get(4))
fps = vcap.get(5)
fourcc = cv2.VideoWriter_fourcc(*'MP4V') #codec
video=cv2.VideoWriter(output_video_path, fourcc, fps, (width,height))
frame_id = 0
# Capture frame-by-frame
ret, frame = vcap.read() # ret = 1 if the video is captured; frame is the image
while ret:
df = detections
df = df[['Face.bbox', 'gendercnn.label']][df['tiktok.id'] == frame_id]
if df.size:
for bbox, label in df.values:
x1, y1, x2, y2 = bbox
x1, y1, x2, y2 = int(x1), int(y1), int(x2), int(y2)
frame=cv2.rectangle(frame, (x1, y1), (x2, y2), color, thickness) # object bbox
cv2.putText(frame, str(label), (x1, y1-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, color, thickness-1) # object label
video.write(frame)
# Show every fifth frame
if frame_id % 5 == 0:
plt.imshow(frame)
plt.show()
if frame_id == 50:
return
frame_id+=1
ret, frame = vcap.read()
video.release()
vcap.release()
#!pip install ipywidgets
from ipywidgets import Video
input_path = 'short.mp4'
output_path = 'annotated_short.mp4'
dataframe = response.batch.frames
annotate_video(dataframe, input_path, output_path)
OpenCV: FFMPEG: tag 0x5634504d/'MP4V' is not supported with codec id 12 and format 'mp4 / MP4 (MPEG-4 Part 14)'
OpenCV: FFMPEG: fallback to use tag 0x7634706d/'mp4v'